Overview
This project builds a content-based movie recommendation system using the TMDB dataset. It recommends movies based on similarity in metadata such as genres, overview, tagline, and production details.
Instead of using collaborative filtering or deep learning, the system relies on classical NLP techniques and vector space modeling.
Problem Statement
Streaming platforms need recommendation systems to improve content discovery. However, user-based filtering requires large behavioral datasets.
This project solves the cold-start problem by using content-based similarity, where recommendations are generated purely from movie metadata.
Dataset Processing
The dataset (movies_metadata.csv) was cleaned and filtered to retain relevant features.
Selected Columns
title, genres, overview, tagline, vote_average, popularity, id, original_language, production_companies, release_date
Data Cleaning
Steps Performed
- Removed duplicate records
- Dropped rows with missing titles
- Filled missing values in:
- overview → empty string
- tagline → empty string
- original_language → empty string
- release_date → empty string
df = df.drop_duplicates().reset_index(drop=True)
df = df.dropna(subset=['title'])
df['overview'] = df['overview'].fillna('')
df['tagline'] = df['tagline'].fillna('')Feature Engineering
Genre & Production Parsing
The dataset stores structured JSON-like strings, converted using ast.literal_eval.
import ast
df['genres'] = df['genres'].apply(
lambda x: " ".join([i['name'] for i in ast.literal_eval(x)])
)
df['production_companies'] = df['production_companies'].apply(
lambda x: " ".join([i['name'] for i in ast.literal_eval(x)])
)Feature Combination
All important text features were merged into a single field:
df['combined_features'] = df['genres'] + ' ' + df['overview'] + ' ' + df['tagline']This ensures that all semantic signals are captured in one representation.
NLP Preprocessing
A custom text preprocessing pipeline was applied:
Steps:
- Lowercasing
- Removing punctuation (regex)
- Stopword removal
- Stemming using Porter Stemmer
def preprocess_text(text):
text = str(text).lower()
text = re.sub(r'[^\w\s]', ' ', text)
words = text.split()
words = [word for word in words if word not in stop_words]
words = [ps.stem(word) for word in words]
return ' '.join(words)Vectorization (TF-IDF)
Text data is converted into numerical vectors using TF-IDF.
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(
max_features=50000,
ngram_range=(1,2),
stop_words='english'
)
tfidf_matrix = tfidf.fit_transform(df['combined_features'])Why TF-IDF?
Captures importance of words Reduces influence of common words Works well for similarity-based systems Similarity Calculation
Cosine similarity is used to measure distance between movie vectors.
- Each movie is represented as a vector
- Similarity is computed by angle between vectors
- Recommendation Engine
- Index Mapping
indices = pd.Series(df.index, index=df['title']).drop_duplicates()Recommendation Function
from sklearn.metrics.pairwise import cosine_similarity
def recommend(movie, n=10):
movie = movie.title()
if movie not in indices:
return ["Movie not found"]
idx = indices[movie]
sim_score = cosine_similarity(tfidf_matrix[idx], tfidf_matrix).flatten()
similar_idx = sim_score.argsort()[::-1][1:n+1]
return df['title'].iloc[similar_idx]Model Persistence (Deployment Ready)
The trained components are saved using pickle:
import pickle
pickle.dump(tfidf_matrix, open('tfidf_matrix.pkl', 'wb'))
pickle.dump(indices, open('indices.pkl', 'wb'))
pickle.dump(tfidf, open('tfidf.pkl', 'wb'))
df.to_pickle('df.pkl')Saved Artifacts
- TF-IDF Vectorizer (vocabulary)
- TF-IDF Matrix (learned representation)
- Index mapping (title → row index)
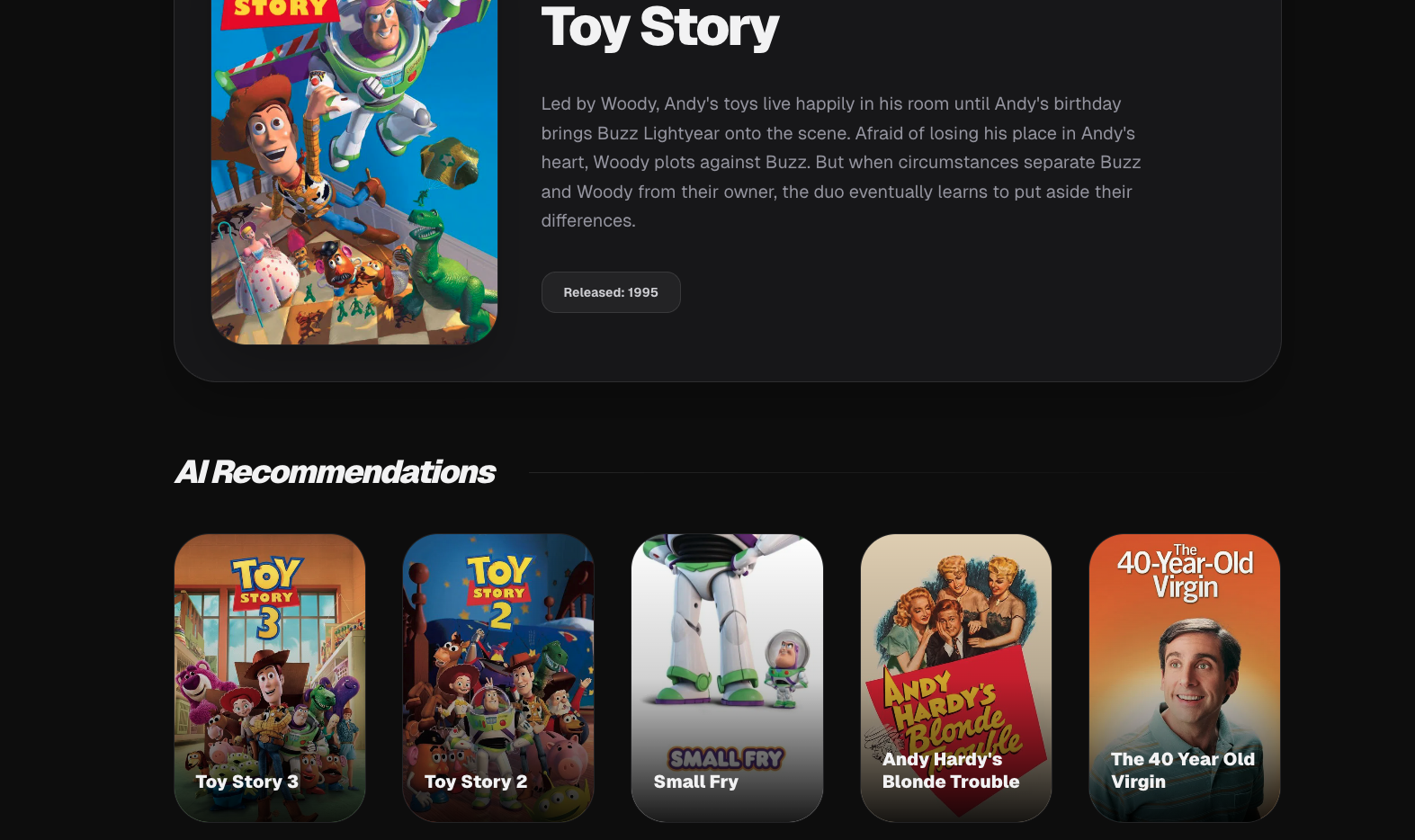
- Dataset (metadata storage) Example Output
Input:
Toy StoryOutput:
- Similar Movie 1
- Similar Movie 2
- Similar Movie 3
- ....
Key Insight
This system demonstrates that strong recommendations can be built without deep learning or user behavior data purely using statistical NLP and vector similarity.
Deployment
The recommendation logic was exposed using a FastAPI backend, which serves movie suggestions through REST APIs. The frontend was built using Next.js and fetches real-time recommendations from the backend. The backend is deployed on Render, while the frontend is hosted on Vercel for production use. The final system is fully functional, allowing users to search any movie and receive instant recommendations based on content similarity.
Live Demo
https://movie-recomendation-using-cosine-si.vercel.app/
You can search any movie and instantly get recommendations powered by TF-IDF + cosine similarity. The free tire is used so you may feel the performance issue.